Architecting Network Connectivity for a Zero Trust Future
Alex Marshall
•
Jan 12, 2022
Since launching Twingate in 2020, we’ve been fortunate to work with some of the fastest-growing companies in the world. These companies work on the bleeding edge of technology, and one of the most common discussions we have is how network connectivity will evolve to fully realize the potential of Zero Trust. Today, we want to share our views on where network architectures are headed in a Zero Trust world and introduce new enhancements to Twingate.
First off, we’re excited to announce several technical enhancements to Twingate that bring several modern networking technologies into our core networking engine. These include leveraging NAT traversal to facilitate direct, peer-to-peer connections between nodes in your Twingate network, and introducing QUIC, a modern network transport protocol that offers more resilient, lower latency connections.
These enhancements allow us to clarify how we believe network architectures will evolve in the coming years as Zero Trust principles become more widely implemented. We’ll start with a quick review of a traditional network architecture using VPN for remote access, discuss the cloud-based architecture used by most vendors today, and walk-through Twingate’s distributed network architecture and the underlying techniques we’ve used to bring this architecture to life.
Traditional Network with VPN
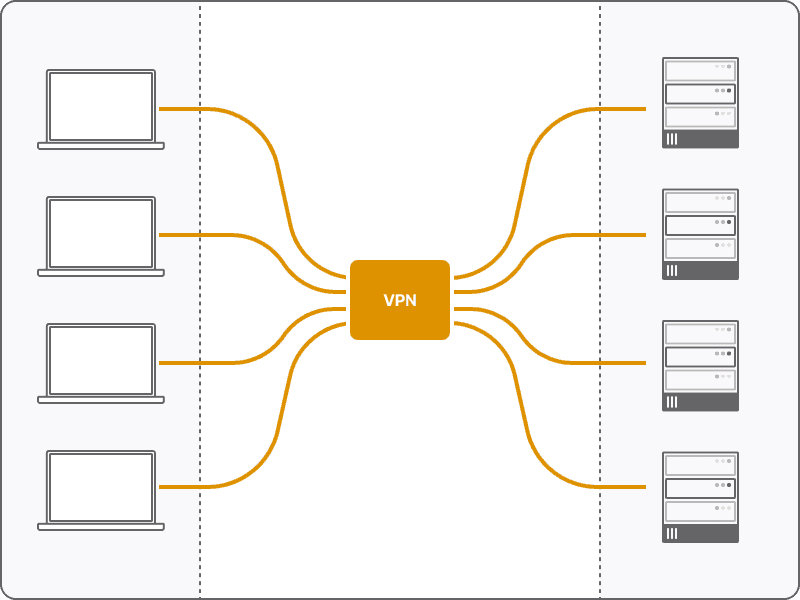
Traditional Network with VPN
VPN first came into broad usage in the 1990s. It is still the dominant technology used for remote access into corporate networks when users are not physically connected to the corporate network (usually at the company’s office). In this architecture, a VPN gateway is deployed at the edge of a private network and acts as an entry point for remote users who need access to resources on that network.
Companies often configure a single VPN into the corporate network and then set up secondary tunnels between other networks, which may be in different geographic locations. In this model, the VPN gateway acts as a concentrator for any remote user to enter the private network before being routed to their final destination. This results in a hub-and-spoke network topology that creates several problems:
The VPN gateway sits at the edge of the private network with a public IP address, exposing it to the public internet. This makes VPN gateways susceptible to attackers, particularly when vulnerabilities are discovered. Unfortunately, these vulnerabilities are discovered frequently and are commonly exploited by adversaries.
Because users can only connect to a single VPN gateway before their traffic is routed to its final destination, a significant performance hit often occurs as users bounce around geographically distributed locations before reaching the destination resource.
Remote VPN users are typically given full access to the private network, which creates a large blast radius if a remote user is compromised or an attacker breaches the public VPN gateway.
Because of this, companies and IT teams often jump through tremendous hoops to secure these inherent design flaws. For example, companies will usually increase the number of VPN gateways to solve performance challenges, creating an even larger public attack surface to secure.
While many companies have begrudgingly tolerated these design flaws, designing around them when possible, the movement to the cloud and the demand from employees to work from anywhere have put significant pressure on IT and security teams who are forced to manage and secure this legacy network architecture.
Cloud-based Networks and the PoP Race
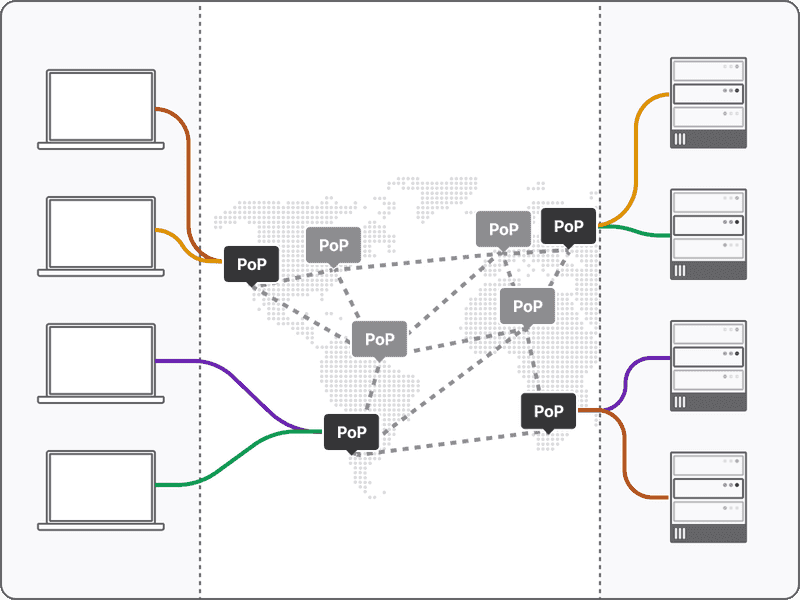
Cloud-based Networks
In the 2010s, a new crop of vendors emerged that attempted to solve these challenges by taking the on-prem private network managed by the company’s IT team and shifting it to a hosted network managed by the vendor. In this architecture, VPN gateways are replaced by Points-of-Presence (PoPs) that are geographically distributed and managed by the vendor.
With this approach, the vendor’s private cloud network sits between users and company resources. Remote users need to first connect to the vendor’s nearest PoP before being routed to the final destination. To provide performance improvements over the traditional model, vendors offering this network architecture are in a perpetual race to build as many PoPs as possible (to be geographically close to users) and maintain and upgrade the network backbone between PoPs.
However, even the largest vendors using this model have PoPs in the low 100s. Depending on the geographic distribution of a company’s workforce and the location of resources, this network architecture can improve the traditional network model. However, this model still puts the customer’s network performance at the mercy of how well a vendor’s distributed PoP footprint aligns with the company’s needs.
Depending on the specific vendor’s implementation, other downsides with this model may include:
Inability to work for all protocols or resource types: Some implementations of this model are optimized for web-based resources accessed through a browser. This means it is difficult (and in some cases impossible) to use these solutions for applications and protocols like SSH and database clients.
Hard to integrate: These solutions will often require a complex implementation process so that a company’s private network is connected to the vendor’s network. This may require complex configuration and management of dedicated VPN tunnels, challenges with configuring DNS, and other points of deployment friction.
Distributed Networks for a Distributed World
With Twingate, we designed a network architecture with the underlying assumption that users and resources are both highly distributed and in constant motion. We believe that the ideal network architecture for this distributed world must allow network traffic to flow directly between nodes without traversing any intermediate nodes or networks.
This also means that our customers’ network performance is not limited by our ability to geographically scale-out a large footprint of PoPs in far-flung locations. This brings cloud-based architecture to its logical end state and effectively puts a local PoP on every device.
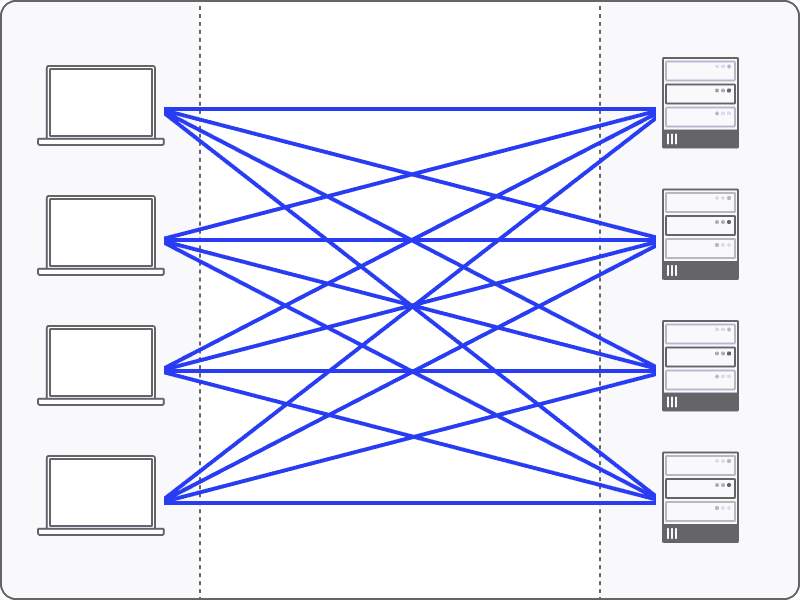
Distributed Network with local PoP on every device
To make all of this work, we need a new network architecture. While several widely accepted frameworks are available, which we gleaned inspiration from, they did not align with our Zero Trust principles. The frameworks we researched and assessed include Software-Defined Perimeter (SDP), mesh networks, and Software-Defined Networking (SDN). Twingate’s architecture has elements of all these frameworks, and we’ve specifically focused on making design decisions that optimize for performance and security without compromising ease of deployment.
In Twingate’s model, we think about separating our network architecture into three primary concepts:
The network layer: The set of resources and devices that need to connect to each other
The control layer: Permissions and access rules that determine which users and resources are permitted to communicate
The transport layer: The enabling mechanisms and routes for data to move between users and resources
In a traditional network design, these concepts are tightly coupled and often result in tradeoffs that manifest in some combination of low performance, poor security controls, difficulty in deployment and management, or all of the above. Instead, we decided to decouple each of those concepts into separate layers that allow us to optimize the behavior of each layer to produce the maximum benefit, whether that is connection performance or security controls.
We describe this as a distributed network architecture, and we believe that this will become the standard way companies will design and manage access to their networks over the coming years.
Let’s take a look at each of these layers and describe how they work in the context of Twingate:
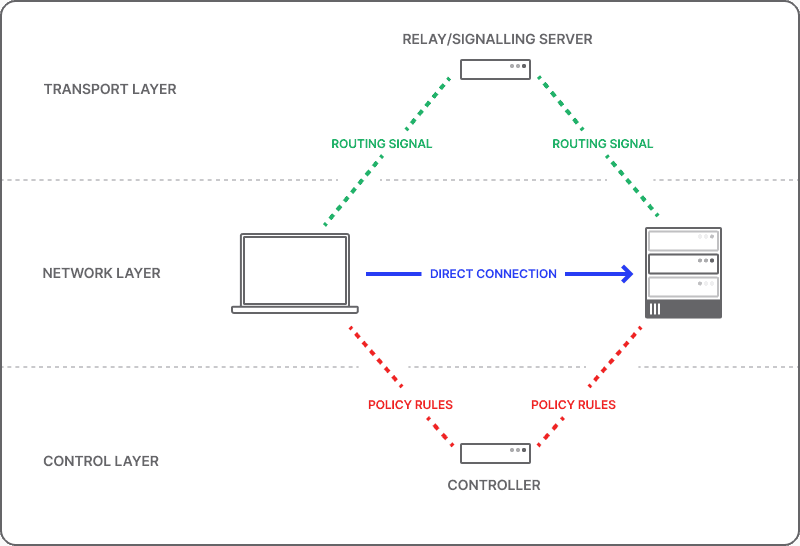
Three layers of Twingate network architecture
The Network Layer
This refers to the complete set of resources and devices that can potentially connect to each other. No existing interconnection between this set of nodes is necessary and individual nodes in this layer can exist in any network or geography. The combination of the control and transport layers (described below) ensures that only authorized clients can access assigned resources.
Clients and resources can access the control and transport layers directly via an embedded library, client application, or a lightweight proxy. These components perform a few critical functions:
Policy enforcement: rules passed down by the control layer are enforced locally without any traffic needing to leave the device.
Routing: route selections are executed locally to deliver the best connectivity performance.
Security: implement security controls such as enforcing allow/deny lists or implementing secure DNS.
Most importantly, no node in the network needs to be exposed to the public internet.
The Control Layer
This layer is responsible for defining the rules governing which nodes in the network can communicate with each other. While this control layer needs to be distributed and redundant to serve low latency requests to clients and resources, no traffic passes through this layer.
The control layer performs a few critical functions:
Authentication: users and clients cannot access resources without first authenticating themselves. This is enforced and enabled by the control layer, and it interfaces to an identity authority (e.g., Okta) for authentication.
Policy definition: policies are defined in the control layer (e.g., via a web-based admin console or the admin API) and subsequently passed down to the network nodes for enforcement and execution.
The Transport Layer
This layer is responsible for facilitating the optimal route from any client to any resource and serves two primary functions:
Signaling channel for peer-to-peer connections: By default, the transport layer attempts to establish a direct, peer-to-peer connection between the client and the resource. This is achieved by using a signaling channel to directly orchestrate a connection between the two nodes. If either or both nodes are behind a firewall, then a range of NAT traversal techniques are used to establish a direct, end-to-end encrypted connection between client and resource.
Serves as a backup transport channel to relay encrypted traffic: If a peer-to-peer connection cannot be established, the transport layer can take over relaying encrypted traffic between the client and resource. Although this appears similar in structure to the Cloud Network architecture described above, a key difference is that all routing and authorization decisions are made directly in the client and resource nodes. These decisions are enabled by the control layer and executed by the client and resource nodes, which relegates the transport layer to a zero-knowledge transfer of encrypted bytes.
In aggregate, the decoupling of these concepts into discrete concepts enables us to drive towards the optimal combination performance, security controls, and ease of management.
Next, we’ll dive deeper into the underlying network techniques to bring this architecture to life.
Twingate’s Distributed Network Architecture
As we’ve worked to implement our version of the distributed network topology, we’ve employed a range of techniques that provide optimal performance in most scenarios and reflect the reality of how people work today.
It all starts with Routing
The first problem is routing. How do you get a network connection established from a client to a resource? The easiest solution would involve every device on the Internet having a unique address so that network connections could be directly routable between any two devices. Although this is how the Internet started, with every host uniquely accessible, it was clear as early as 1992 that every unique address in the IPv4 space would soon be exhausted. With inevitable Internet address exhaustion on the horizon, a number of solutions were proposed, including Network Address Translation (NAT), which was proposed in 1994 and adopted soon thereafter. NAT was intended to be a short-term solution, with IPv6 being the long-term solution to address exhaustion. The last block of IPv4 addresses was assigned in 2011, and in 2021 we’re still waiting for the complete adoption of IPv6. NAT and IPv4 will be with us for some time to come.
For most use cases, NAT doesn’t present any particular problems. Without realizing it, everyone who uses the Internet today has their traffic constantly traversing multiple layers of NAT to access public Internet services. In this situation, a private host (a user’s device) is accessing a public host (e.g., a web server). Traffic can be exchanged by virtue of the public host having a publicly accessible endpoint that’s routable from the private host via an ISP.
Where things get interesting is when one private host wants to connect to another private host—known as a peer-to-peer connection—where, for example, two participants wish to initiate a video call, each at home behind the NAT service on their home router. Several technologies have been developed to address the issue of NAT traversal—so-called because each peer must traverse the NAT layer in front of its peer—since the earlier days of the Internet. WebRTC is one of the most well-known approaches. We’ll come back to this topic of NAT traversal techniques later on.
In our distributed network architecture, the control layer authorizes connections from any client to any resource in the network layer. If this is the end goal, and we can’t control whether clients and resources are behind a NAT layer, how can a client connect to a resource under those conditions? It turns out that there are several approaches, which we’ll go through in progressive order of complexity.
Open access: The simplest possible option is that everything should have a public IP address, which means that connecting any two hosts requires routing and nothing else. This isn’t as crazy as it sounds, but it does require a significant rethinking of how individual hosts are secured from attack by default, so this isn’t practical on today’s Internet. In the future, IPv6 will make this option more realistic.
Port forwarding: A relatively simple approach that questionably relies on security through obscurity. The approach taken here is to translate from some public IP address (your home internet router, for example) and a designated port that forwards traffic through to a private address and different port. This exposes only the necessary service(s) that you wish to make available and makes the destination routable to the public internet. Still, this approach leaves the target service and host open to public attack vectors and involves the configuration of router rules, which adds unnecessary complexity at any kind of scale.
Port knocking: Also known as Secure Packet Authorization (SPA), this technique is akin to having a secret knock to enter a Prohibition-era speakeasy, hence the technique’s name. While the actual implementation is more complex, the goal is to deter casual port scanners by leaving open ports unresponsive unless a particular sequence and timing of packets arrive to open up the specific port. It’s an effective technique, but one that leaves your host and services wide open if the packet sequence is discovered.
Data relay: Instead of developing techniques that involve opening up access to the target host from the public Internet, using a relay introduces an intermediate host publicly accessible from both the client and resource hosts. This has the advantage that the client and resource hosts can remain invisible to the public Internet. As long as a relay is available close to either host, minimal additional latency is introduced. The relay can be incorporated into the overall transport such that no connection termination occurs and streams can remain private. This approach is a standard backup method when NAT traversal techniques are unsuccessful.
Proxies: With the introduction of proxies, we’ve now departed the realm of solutions-driven purely by the routing and transport layers of networks. Proxies work by terminating network connections, either manipulating or validating the packets and payloads they receive, and sending that data forward to either a destination resource or a corresponding reverse proxy, passing data to the destination resource.
Proxies are software-based and operate in the operating system’s user space. Proxies are easily deployed and introduce a significant level of sophistication into the type of routing and transport manipulation that’s possible while often remaining transparent to the application initiating a network connection. For these reasons, proxies are the dominant solution deployed today across many applications involving network traffic management.
There are two approaches taken to deploying proxies in practice. While their underlying functionality may be identical, they differ in the tradeoffs made in their deployment.
Public proxies: Public proxies are deployed with a publicly routable address, which means that they can sit in front of a destination resource, making it accessible from clients regardless of whether they have publicly accessible addresses or not. The tradeoff here is that with the convenience of accessibility comes the burden of ensuring that the public proxy is hardened and regularly patched to prevent attacks. This is particularly true because of the role the proxy plays: if identified as a proxy from the outside, it’s an entry point that is securing something in the private network behind it.
Private proxies: Private proxies serve the same role, but they are deployed behind firewalls on a private network. There are significant security benefits to this approach—no public address and all the benefits of using a proxy in the first place—but they don’t address the issue of making resources accessible to clients because they, too, are behind a firewall. This leads us to the topic of NAT traversal, which we’ll cover next.
Punching Holes Through (Fire)walls
Since we ended with private proxies in our overview above, it’s a safe bet that we think private proxies represent the best set of tradeoffs for implementing a distributed network topology. The two primary reasons for this are that private proxies are:
Invisible to the public internet: Because they sit behind a private network’s firewall, it’s impossible to discover them via public Internet port scanning or probe them for vulnerabilities. Even if a sophisticated attacker can infer the existence of a proxy behind a firewall based on visible traffic patterns, defense in depth is a highly effective technique here by separating security concerns into an effective firewall.
Simple to deploy: Since they run as a regular user space service, they’re effortless to deploy onto virtually any available device, regardless of platform or silicon chipset. The lower security burden of private proxies also means that they’re more likely to be deployed when needed. Successful adoption of a given approach is also an essential factor in overall security posture.
The last puzzle piece is figuring out how to make these proxies accessible to clients who wish to connect to the destination resources they protect: enter NAT traversal. Because NAT has been implemented across Internet-connected networks for several decades, the range of solutions available to solve the problem of two hosts, each behind a NAT layer, establishing a peer-to-peer connection is fairly mature today. We won’t go into depth here but instead, cover the high-level steps involved in establishing a peer-to-peer connection via NAT traversal.
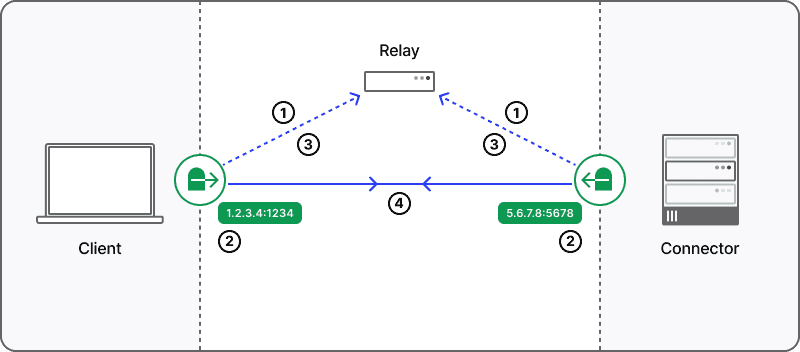
Twingate NAT traversal process
The NAT traversal process is divided into four primary stages:
Establish a signaling channel: On initial startup, both the client and private proxy—known as the connector in Twingate’s architecture—initiate and establish an authenticated connection to a central service that is publicly accessible. The initial role of this service is to establish a signaling channel for the exchange of peer candidate addresses to each peer. In Twingate’s architecture, our existing authenticated relay infrastructure—already distributed globally—is used to establish a signaling channel.
Discover peer candidate addresses: For the client to negotiate a peer-to-peer connection with a connector, both peers must discover their public IP:port address assigned by the NAT layer. A STUN server facilitates this process and is hosted on our relay infrastructure.
Exchange candidate peer addresses: Each peer next receives one or more candidate addresses for its peer via the signaling channel. The connector will receive candidate address(es) for the client and vice-versa.
Negotiate & establish the connection: The peer candidate addresses are used by the partner peer to attempt to establish a direct peer-to-peer connection and complete the NAT traversal process.
Putting it all together
It’s not always possible to establish a direct peer-to-peer connection for various reasons, from blocked ports to incompatible NAT layers. In that case, a backup data transport method needs to be maintained. In Twingate’s case, this is a data relay infrastructure that operates in the transport layer of our network architecture. Relays have public addresses, so they are always accessible from clients and deployed connectors, serving as a reliable backup transport method.
In summary:
Private proxies provide the best set of tradeoffs between security and flexibility to specifically deploy into the private networks where access is needed.
NAT traversal is used to create a peer-to-peer connection between clients and resources to minimize latency.
Relaying infrastructure is available as a backup transport method when NAT traversal is not possible.
Twingate automatically prioritizes the lowest latency transport option that’s available between peers.
One more thing…
We mentioned above that proxies provide the opportunity to introduce a significant level of sophistication into network traffic management. We’ve taken advantage of that to introduce QUIC, a new transport layer network protocol, into our peer-to-peer connections. QUIC introduces several improvements to our transport layer, including faster connection establishment, greater tolerance to network changes—a dominant mode standard in today’s world of mobile devices—and more effective traffic management of multiple, concurrent data streams. User space network stack implementations like QUIC can evolve more quickly than their kernel space counterparts, and we’re excited to participate in this fast-paced evolution.
QUIC was originally developed by Google and has since been standardized by IETF in RFC 9000 and proposed as the underlying transport protocol for HTTP/3. One of the primary goals of QUIC was to become a better transport mechanism for HTTP/2, which suffers from the so-called head of line blocking problem due to its use of TCP as the underlying transport protocol. The head of line blocking problem occurs when all HTTP/2 streams multiplexed over a single TCP connection are impacted by retransmission due to packet loss affecting only a subset of streams.
QUIC is built on top of UDP, which is an unreliable network protocol, and so it provides its own reliable delivery mechanisms. QUIC provides reliable and ordered delivery of multiple concurrent data streams by multiplexing them over a single connection.
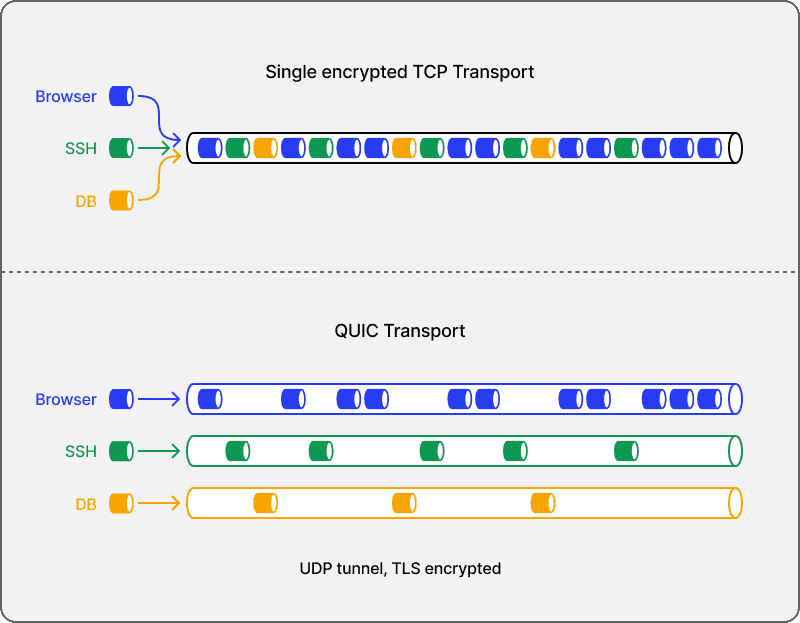
Twingate's QUIC Transport
Although TCP implementations have been highly optimized over many years, for many users and use cases, QUIC’s low latency is arguably more critical than raw throughput, and QUIC can match or exceed TCP+TLS in this respect. Thanks to QUIC’s adoption, there are also ongoing efforts to optimize UDP performance in the Linux kernel, which will further improve performance in the future.
The motivation behind the development of QUIC—to improve the throughput of multiple streams on a single reliable connection—is also valuable to maximizing throughput from the Twingate client to multiple private resources. Although QUIC was envisioned to optimize the throughput of multiple streams for a single application (e.g., your browser), Twingate extends this concept by mapping individual data flows from any number of applications to single QUIC streams and delivering those data flows to connectors and resources deployed anywhere in our distributed architecture.
Beyond performance management for multiple data flows, adopting QUIC also introduces several valuable improvements to our network architecture:
Faster connection establishment: The initial connection takes a single round trip between client and server. Connection resumption can also be done without any additional round-trip negotiation.
Support for the latest cryptographic protocols: QUIC only supports TLS 1.3 and later, and introduces additional security into the encrypted channel.
Client-side roaming: QUIC connections survive client-side IP and port changes—for example, due to NAT rebinding or a user switching between networks—which not only results in a better experience for users but is also better suited for today’s mobile work environment.
Incorporates best practices from TCP: Although QUIC is a UDP-based protocol, it contains the best practices learned over the long history of the TCP protocol without being restricted by TCP’s legacy (e.g., packet format). For example, QUIC is usually more efficient than TCP in dealing with packet loss recovery.
Try Twingate for Free
We’re thrilled by the reception Twingate has received since our launch in 2020. If you’re interested in taking Twingate for a spin, we just launched a free tier where you can implement our secure access solution for your startup, home network, or personal projects. Of course, we also have business plans if you’re interested in moving off VPN for your company.
Rapidly implement a modern Zero Trust network that is more secure and maintainable than VPNs.
Architecting Network Connectivity for a Zero Trust Future
Alex Marshall
•
Jan 12, 2022
Since launching Twingate in 2020, we’ve been fortunate to work with some of the fastest-growing companies in the world. These companies work on the bleeding edge of technology, and one of the most common discussions we have is how network connectivity will evolve to fully realize the potential of Zero Trust. Today, we want to share our views on where network architectures are headed in a Zero Trust world and introduce new enhancements to Twingate.
First off, we’re excited to announce several technical enhancements to Twingate that bring several modern networking technologies into our core networking engine. These include leveraging NAT traversal to facilitate direct, peer-to-peer connections between nodes in your Twingate network, and introducing QUIC, a modern network transport protocol that offers more resilient, lower latency connections.
These enhancements allow us to clarify how we believe network architectures will evolve in the coming years as Zero Trust principles become more widely implemented. We’ll start with a quick review of a traditional network architecture using VPN for remote access, discuss the cloud-based architecture used by most vendors today, and walk-through Twingate’s distributed network architecture and the underlying techniques we’ve used to bring this architecture to life.
Traditional Network with VPN
Traditional Network with VPN
VPN first came into broad usage in the 1990s. It is still the dominant technology used for remote access into corporate networks when users are not physically connected to the corporate network (usually at the company’s office). In this architecture, a VPN gateway is deployed at the edge of a private network and acts as an entry point for remote users who need access to resources on that network.
Companies often configure a single VPN into the corporate network and then set up secondary tunnels between other networks, which may be in different geographic locations. In this model, the VPN gateway acts as a concentrator for any remote user to enter the private network before being routed to their final destination. This results in a hub-and-spoke network topology that creates several problems:
The VPN gateway sits at the edge of the private network with a public IP address, exposing it to the public internet. This makes VPN gateways susceptible to attackers, particularly when vulnerabilities are discovered. Unfortunately, these vulnerabilities are discovered frequently and are commonly exploited by adversaries.
Because users can only connect to a single VPN gateway before their traffic is routed to its final destination, a significant performance hit often occurs as users bounce around geographically distributed locations before reaching the destination resource.
Remote VPN users are typically given full access to the private network, which creates a large blast radius if a remote user is compromised or an attacker breaches the public VPN gateway.
Because of this, companies and IT teams often jump through tremendous hoops to secure these inherent design flaws. For example, companies will usually increase the number of VPN gateways to solve performance challenges, creating an even larger public attack surface to secure.
While many companies have begrudgingly tolerated these design flaws, designing around them when possible, the movement to the cloud and the demand from employees to work from anywhere have put significant pressure on IT and security teams who are forced to manage and secure this legacy network architecture.
Cloud-based Networks and the PoP Race
Cloud-based Networks
In the 2010s, a new crop of vendors emerged that attempted to solve these challenges by taking the on-prem private network managed by the company’s IT team and shifting it to a hosted network managed by the vendor. In this architecture, VPN gateways are replaced by Points-of-Presence (PoPs) that are geographically distributed and managed by the vendor.
With this approach, the vendor’s private cloud network sits between users and company resources. Remote users need to first connect to the vendor’s nearest PoP before being routed to the final destination. To provide performance improvements over the traditional model, vendors offering this network architecture are in a perpetual race to build as many PoPs as possible (to be geographically close to users) and maintain and upgrade the network backbone between PoPs.
However, even the largest vendors using this model have PoPs in the low 100s. Depending on the geographic distribution of a company’s workforce and the location of resources, this network architecture can improve the traditional network model. However, this model still puts the customer’s network performance at the mercy of how well a vendor’s distributed PoP footprint aligns with the company’s needs.
Depending on the specific vendor’s implementation, other downsides with this model may include:
Inability to work for all protocols or resource types: Some implementations of this model are optimized for web-based resources accessed through a browser. This means it is difficult (and in some cases impossible) to use these solutions for applications and protocols like SSH and database clients.
Hard to integrate: These solutions will often require a complex implementation process so that a company’s private network is connected to the vendor’s network. This may require complex configuration and management of dedicated VPN tunnels, challenges with configuring DNS, and other points of deployment friction.
Distributed Networks for a Distributed World
With Twingate, we designed a network architecture with the underlying assumption that users and resources are both highly distributed and in constant motion. We believe that the ideal network architecture for this distributed world must allow network traffic to flow directly between nodes without traversing any intermediate nodes or networks.
This also means that our customers’ network performance is not limited by our ability to geographically scale-out a large footprint of PoPs in far-flung locations. This brings cloud-based architecture to its logical end state and effectively puts a local PoP on every device.
Distributed Network with local PoP on every device
To make all of this work, we need a new network architecture. While several widely accepted frameworks are available, which we gleaned inspiration from, they did not align with our Zero Trust principles. The frameworks we researched and assessed include Software-Defined Perimeter (SDP), mesh networks, and Software-Defined Networking (SDN). Twingate’s architecture has elements of all these frameworks, and we’ve specifically focused on making design decisions that optimize for performance and security without compromising ease of deployment.
In Twingate’s model, we think about separating our network architecture into three primary concepts:
The network layer: The set of resources and devices that need to connect to each other
The control layer: Permissions and access rules that determine which users and resources are permitted to communicate
The transport layer: The enabling mechanisms and routes for data to move between users and resources
In a traditional network design, these concepts are tightly coupled and often result in tradeoffs that manifest in some combination of low performance, poor security controls, difficulty in deployment and management, or all of the above. Instead, we decided to decouple each of those concepts into separate layers that allow us to optimize the behavior of each layer to produce the maximum benefit, whether that is connection performance or security controls.
We describe this as a distributed network architecture, and we believe that this will become the standard way companies will design and manage access to their networks over the coming years.
Let’s take a look at each of these layers and describe how they work in the context of Twingate:
Three layers of Twingate network architecture
The Network Layer
This refers to the complete set of resources and devices that can potentially connect to each other. No existing interconnection between this set of nodes is necessary and individual nodes in this layer can exist in any network or geography. The combination of the control and transport layers (described below) ensures that only authorized clients can access assigned resources.
Clients and resources can access the control and transport layers directly via an embedded library, client application, or a lightweight proxy. These components perform a few critical functions:
Policy enforcement: rules passed down by the control layer are enforced locally without any traffic needing to leave the device.
Routing: route selections are executed locally to deliver the best connectivity performance.
Security: implement security controls such as enforcing allow/deny lists or implementing secure DNS.
Most importantly, no node in the network needs to be exposed to the public internet.
The Control Layer
This layer is responsible for defining the rules governing which nodes in the network can communicate with each other. While this control layer needs to be distributed and redundant to serve low latency requests to clients and resources, no traffic passes through this layer.
The control layer performs a few critical functions:
Authentication: users and clients cannot access resources without first authenticating themselves. This is enforced and enabled by the control layer, and it interfaces to an identity authority (e.g., Okta) for authentication.
Policy definition: policies are defined in the control layer (e.g., via a web-based admin console or the admin API) and subsequently passed down to the network nodes for enforcement and execution.
The Transport Layer
This layer is responsible for facilitating the optimal route from any client to any resource and serves two primary functions:
Signaling channel for peer-to-peer connections: By default, the transport layer attempts to establish a direct, peer-to-peer connection between the client and the resource. This is achieved by using a signaling channel to directly orchestrate a connection between the two nodes. If either or both nodes are behind a firewall, then a range of NAT traversal techniques are used to establish a direct, end-to-end encrypted connection between client and resource.
Serves as a backup transport channel to relay encrypted traffic: If a peer-to-peer connection cannot be established, the transport layer can take over relaying encrypted traffic between the client and resource. Although this appears similar in structure to the Cloud Network architecture described above, a key difference is that all routing and authorization decisions are made directly in the client and resource nodes. These decisions are enabled by the control layer and executed by the client and resource nodes, which relegates the transport layer to a zero-knowledge transfer of encrypted bytes.
In aggregate, the decoupling of these concepts into discrete concepts enables us to drive towards the optimal combination performance, security controls, and ease of management.
Next, we’ll dive deeper into the underlying network techniques to bring this architecture to life.
Twingate’s Distributed Network Architecture
As we’ve worked to implement our version of the distributed network topology, we’ve employed a range of techniques that provide optimal performance in most scenarios and reflect the reality of how people work today.
It all starts with Routing
The first problem is routing. How do you get a network connection established from a client to a resource? The easiest solution would involve every device on the Internet having a unique address so that network connections could be directly routable between any two devices. Although this is how the Internet started, with every host uniquely accessible, it was clear as early as 1992 that every unique address in the IPv4 space would soon be exhausted. With inevitable Internet address exhaustion on the horizon, a number of solutions were proposed, including Network Address Translation (NAT), which was proposed in 1994 and adopted soon thereafter. NAT was intended to be a short-term solution, with IPv6 being the long-term solution to address exhaustion. The last block of IPv4 addresses was assigned in 2011, and in 2021 we’re still waiting for the complete adoption of IPv6. NAT and IPv4 will be with us for some time to come.
For most use cases, NAT doesn’t present any particular problems. Without realizing it, everyone who uses the Internet today has their traffic constantly traversing multiple layers of NAT to access public Internet services. In this situation, a private host (a user’s device) is accessing a public host (e.g., a web server). Traffic can be exchanged by virtue of the public host having a publicly accessible endpoint that’s routable from the private host via an ISP.
Where things get interesting is when one private host wants to connect to another private host—known as a peer-to-peer connection—where, for example, two participants wish to initiate a video call, each at home behind the NAT service on their home router. Several technologies have been developed to address the issue of NAT traversal—so-called because each peer must traverse the NAT layer in front of its peer—since the earlier days of the Internet. WebRTC is one of the most well-known approaches. We’ll come back to this topic of NAT traversal techniques later on.
In our distributed network architecture, the control layer authorizes connections from any client to any resource in the network layer. If this is the end goal, and we can’t control whether clients and resources are behind a NAT layer, how can a client connect to a resource under those conditions? It turns out that there are several approaches, which we’ll go through in progressive order of complexity.
Open access: The simplest possible option is that everything should have a public IP address, which means that connecting any two hosts requires routing and nothing else. This isn’t as crazy as it sounds, but it does require a significant rethinking of how individual hosts are secured from attack by default, so this isn’t practical on today’s Internet. In the future, IPv6 will make this option more realistic.
Port forwarding: A relatively simple approach that questionably relies on security through obscurity. The approach taken here is to translate from some public IP address (your home internet router, for example) and a designated port that forwards traffic through to a private address and different port. This exposes only the necessary service(s) that you wish to make available and makes the destination routable to the public internet. Still, this approach leaves the target service and host open to public attack vectors and involves the configuration of router rules, which adds unnecessary complexity at any kind of scale.
Port knocking: Also known as Secure Packet Authorization (SPA), this technique is akin to having a secret knock to enter a Prohibition-era speakeasy, hence the technique’s name. While the actual implementation is more complex, the goal is to deter casual port scanners by leaving open ports unresponsive unless a particular sequence and timing of packets arrive to open up the specific port. It’s an effective technique, but one that leaves your host and services wide open if the packet sequence is discovered.
Data relay: Instead of developing techniques that involve opening up access to the target host from the public Internet, using a relay introduces an intermediate host publicly accessible from both the client and resource hosts. This has the advantage that the client and resource hosts can remain invisible to the public Internet. As long as a relay is available close to either host, minimal additional latency is introduced. The relay can be incorporated into the overall transport such that no connection termination occurs and streams can remain private. This approach is a standard backup method when NAT traversal techniques are unsuccessful.
Proxies: With the introduction of proxies, we’ve now departed the realm of solutions-driven purely by the routing and transport layers of networks. Proxies work by terminating network connections, either manipulating or validating the packets and payloads they receive, and sending that data forward to either a destination resource or a corresponding reverse proxy, passing data to the destination resource.
Proxies are software-based and operate in the operating system’s user space. Proxies are easily deployed and introduce a significant level of sophistication into the type of routing and transport manipulation that’s possible while often remaining transparent to the application initiating a network connection. For these reasons, proxies are the dominant solution deployed today across many applications involving network traffic management.
There are two approaches taken to deploying proxies in practice. While their underlying functionality may be identical, they differ in the tradeoffs made in their deployment.
Public proxies: Public proxies are deployed with a publicly routable address, which means that they can sit in front of a destination resource, making it accessible from clients regardless of whether they have publicly accessible addresses or not. The tradeoff here is that with the convenience of accessibility comes the burden of ensuring that the public proxy is hardened and regularly patched to prevent attacks. This is particularly true because of the role the proxy plays: if identified as a proxy from the outside, it’s an entry point that is securing something in the private network behind it.
Private proxies: Private proxies serve the same role, but they are deployed behind firewalls on a private network. There are significant security benefits to this approach—no public address and all the benefits of using a proxy in the first place—but they don’t address the issue of making resources accessible to clients because they, too, are behind a firewall. This leads us to the topic of NAT traversal, which we’ll cover next.
Punching Holes Through (Fire)walls
Since we ended with private proxies in our overview above, it’s a safe bet that we think private proxies represent the best set of tradeoffs for implementing a distributed network topology. The two primary reasons for this are that private proxies are:
Invisible to the public internet: Because they sit behind a private network’s firewall, it’s impossible to discover them via public Internet port scanning or probe them for vulnerabilities. Even if a sophisticated attacker can infer the existence of a proxy behind a firewall based on visible traffic patterns, defense in depth is a highly effective technique here by separating security concerns into an effective firewall.
Simple to deploy: Since they run as a regular user space service, they’re effortless to deploy onto virtually any available device, regardless of platform or silicon chipset. The lower security burden of private proxies also means that they’re more likely to be deployed when needed. Successful adoption of a given approach is also an essential factor in overall security posture.
The last puzzle piece is figuring out how to make these proxies accessible to clients who wish to connect to the destination resources they protect: enter NAT traversal. Because NAT has been implemented across Internet-connected networks for several decades, the range of solutions available to solve the problem of two hosts, each behind a NAT layer, establishing a peer-to-peer connection is fairly mature today. We won’t go into depth here but instead, cover the high-level steps involved in establishing a peer-to-peer connection via NAT traversal.
Twingate NAT traversal process
The NAT traversal process is divided into four primary stages:
Establish a signaling channel: On initial startup, both the client and private proxy—known as the connector in Twingate’s architecture—initiate and establish an authenticated connection to a central service that is publicly accessible. The initial role of this service is to establish a signaling channel for the exchange of peer candidate addresses to each peer. In Twingate’s architecture, our existing authenticated relay infrastructure—already distributed globally—is used to establish a signaling channel.
Discover peer candidate addresses: For the client to negotiate a peer-to-peer connection with a connector, both peers must discover their public IP:port address assigned by the NAT layer. A STUN server facilitates this process and is hosted on our relay infrastructure.
Exchange candidate peer addresses: Each peer next receives one or more candidate addresses for its peer via the signaling channel. The connector will receive candidate address(es) for the client and vice-versa.
Negotiate & establish the connection: The peer candidate addresses are used by the partner peer to attempt to establish a direct peer-to-peer connection and complete the NAT traversal process.
Putting it all together
It’s not always possible to establish a direct peer-to-peer connection for various reasons, from blocked ports to incompatible NAT layers. In that case, a backup data transport method needs to be maintained. In Twingate’s case, this is a data relay infrastructure that operates in the transport layer of our network architecture. Relays have public addresses, so they are always accessible from clients and deployed connectors, serving as a reliable backup transport method.
In summary:
Private proxies provide the best set of tradeoffs between security and flexibility to specifically deploy into the private networks where access is needed.
NAT traversal is used to create a peer-to-peer connection between clients and resources to minimize latency.
Relaying infrastructure is available as a backup transport method when NAT traversal is not possible.
Twingate automatically prioritizes the lowest latency transport option that’s available between peers.
One more thing…
We mentioned above that proxies provide the opportunity to introduce a significant level of sophistication into network traffic management. We’ve taken advantage of that to introduce QUIC, a new transport layer network protocol, into our peer-to-peer connections. QUIC introduces several improvements to our transport layer, including faster connection establishment, greater tolerance to network changes—a dominant mode standard in today’s world of mobile devices—and more effective traffic management of multiple, concurrent data streams. User space network stack implementations like QUIC can evolve more quickly than their kernel space counterparts, and we’re excited to participate in this fast-paced evolution.
QUIC was originally developed by Google and has since been standardized by IETF in RFC 9000 and proposed as the underlying transport protocol for HTTP/3. One of the primary goals of QUIC was to become a better transport mechanism for HTTP/2, which suffers from the so-called head of line blocking problem due to its use of TCP as the underlying transport protocol. The head of line blocking problem occurs when all HTTP/2 streams multiplexed over a single TCP connection are impacted by retransmission due to packet loss affecting only a subset of streams.
QUIC is built on top of UDP, which is an unreliable network protocol, and so it provides its own reliable delivery mechanisms. QUIC provides reliable and ordered delivery of multiple concurrent data streams by multiplexing them over a single connection.
Twingate's QUIC Transport
Although TCP implementations have been highly optimized over many years, for many users and use cases, QUIC’s low latency is arguably more critical than raw throughput, and QUIC can match or exceed TCP+TLS in this respect. Thanks to QUIC’s adoption, there are also ongoing efforts to optimize UDP performance in the Linux kernel, which will further improve performance in the future.
The motivation behind the development of QUIC—to improve the throughput of multiple streams on a single reliable connection—is also valuable to maximizing throughput from the Twingate client to multiple private resources. Although QUIC was envisioned to optimize the throughput of multiple streams for a single application (e.g., your browser), Twingate extends this concept by mapping individual data flows from any number of applications to single QUIC streams and delivering those data flows to connectors and resources deployed anywhere in our distributed architecture.
Beyond performance management for multiple data flows, adopting QUIC also introduces several valuable improvements to our network architecture:
Faster connection establishment: The initial connection takes a single round trip between client and server. Connection resumption can also be done without any additional round-trip negotiation.
Support for the latest cryptographic protocols: QUIC only supports TLS 1.3 and later, and introduces additional security into the encrypted channel.
Client-side roaming: QUIC connections survive client-side IP and port changes—for example, due to NAT rebinding or a user switching between networks—which not only results in a better experience for users but is also better suited for today’s mobile work environment.
Incorporates best practices from TCP: Although QUIC is a UDP-based protocol, it contains the best practices learned over the long history of the TCP protocol without being restricted by TCP’s legacy (e.g., packet format). For example, QUIC is usually more efficient than TCP in dealing with packet loss recovery.
Try Twingate for Free
We’re thrilled by the reception Twingate has received since our launch in 2020. If you’re interested in taking Twingate for a spin, we just launched a free tier where you can implement our secure access solution for your startup, home network, or personal projects. Of course, we also have business plans if you’re interested in moving off VPN for your company.
Rapidly implement a modern Zero Trust network that is more secure and maintainable than VPNs.
Architecting Network Connectivity for a Zero Trust Future
Alex Marshall
•
Jan 12, 2022
Since launching Twingate in 2020, we’ve been fortunate to work with some of the fastest-growing companies in the world. These companies work on the bleeding edge of technology, and one of the most common discussions we have is how network connectivity will evolve to fully realize the potential of Zero Trust. Today, we want to share our views on where network architectures are headed in a Zero Trust world and introduce new enhancements to Twingate.
First off, we’re excited to announce several technical enhancements to Twingate that bring several modern networking technologies into our core networking engine. These include leveraging NAT traversal to facilitate direct, peer-to-peer connections between nodes in your Twingate network, and introducing QUIC, a modern network transport protocol that offers more resilient, lower latency connections.
These enhancements allow us to clarify how we believe network architectures will evolve in the coming years as Zero Trust principles become more widely implemented. We’ll start with a quick review of a traditional network architecture using VPN for remote access, discuss the cloud-based architecture used by most vendors today, and walk-through Twingate’s distributed network architecture and the underlying techniques we’ve used to bring this architecture to life.
Traditional Network with VPN
Traditional Network with VPN
VPN first came into broad usage in the 1990s. It is still the dominant technology used for remote access into corporate networks when users are not physically connected to the corporate network (usually at the company’s office). In this architecture, a VPN gateway is deployed at the edge of a private network and acts as an entry point for remote users who need access to resources on that network.
Companies often configure a single VPN into the corporate network and then set up secondary tunnels between other networks, which may be in different geographic locations. In this model, the VPN gateway acts as a concentrator for any remote user to enter the private network before being routed to their final destination. This results in a hub-and-spoke network topology that creates several problems:
The VPN gateway sits at the edge of the private network with a public IP address, exposing it to the public internet. This makes VPN gateways susceptible to attackers, particularly when vulnerabilities are discovered. Unfortunately, these vulnerabilities are discovered frequently and are commonly exploited by adversaries.
Because users can only connect to a single VPN gateway before their traffic is routed to its final destination, a significant performance hit often occurs as users bounce around geographically distributed locations before reaching the destination resource.
Remote VPN users are typically given full access to the private network, which creates a large blast radius if a remote user is compromised or an attacker breaches the public VPN gateway.
Because of this, companies and IT teams often jump through tremendous hoops to secure these inherent design flaws. For example, companies will usually increase the number of VPN gateways to solve performance challenges, creating an even larger public attack surface to secure.
While many companies have begrudgingly tolerated these design flaws, designing around them when possible, the movement to the cloud and the demand from employees to work from anywhere have put significant pressure on IT and security teams who are forced to manage and secure this legacy network architecture.
Cloud-based Networks and the PoP Race
Cloud-based Networks
In the 2010s, a new crop of vendors emerged that attempted to solve these challenges by taking the on-prem private network managed by the company’s IT team and shifting it to a hosted network managed by the vendor. In this architecture, VPN gateways are replaced by Points-of-Presence (PoPs) that are geographically distributed and managed by the vendor.
With this approach, the vendor’s private cloud network sits between users and company resources. Remote users need to first connect to the vendor’s nearest PoP before being routed to the final destination. To provide performance improvements over the traditional model, vendors offering this network architecture are in a perpetual race to build as many PoPs as possible (to be geographically close to users) and maintain and upgrade the network backbone between PoPs.
However, even the largest vendors using this model have PoPs in the low 100s. Depending on the geographic distribution of a company’s workforce and the location of resources, this network architecture can improve the traditional network model. However, this model still puts the customer’s network performance at the mercy of how well a vendor’s distributed PoP footprint aligns with the company’s needs.
Depending on the specific vendor’s implementation, other downsides with this model may include:
Inability to work for all protocols or resource types: Some implementations of this model are optimized for web-based resources accessed through a browser. This means it is difficult (and in some cases impossible) to use these solutions for applications and protocols like SSH and database clients.
Hard to integrate: These solutions will often require a complex implementation process so that a company’s private network is connected to the vendor’s network. This may require complex configuration and management of dedicated VPN tunnels, challenges with configuring DNS, and other points of deployment friction.
Distributed Networks for a Distributed World
With Twingate, we designed a network architecture with the underlying assumption that users and resources are both highly distributed and in constant motion. We believe that the ideal network architecture for this distributed world must allow network traffic to flow directly between nodes without traversing any intermediate nodes or networks.
This also means that our customers’ network performance is not limited by our ability to geographically scale-out a large footprint of PoPs in far-flung locations. This brings cloud-based architecture to its logical end state and effectively puts a local PoP on every device.
Distributed Network with local PoP on every device
To make all of this work, we need a new network architecture. While several widely accepted frameworks are available, which we gleaned inspiration from, they did not align with our Zero Trust principles. The frameworks we researched and assessed include Software-Defined Perimeter (SDP), mesh networks, and Software-Defined Networking (SDN). Twingate’s architecture has elements of all these frameworks, and we’ve specifically focused on making design decisions that optimize for performance and security without compromising ease of deployment.
In Twingate’s model, we think about separating our network architecture into three primary concepts:
The network layer: The set of resources and devices that need to connect to each other
The control layer: Permissions and access rules that determine which users and resources are permitted to communicate
The transport layer: The enabling mechanisms and routes for data to move between users and resources
In a traditional network design, these concepts are tightly coupled and often result in tradeoffs that manifest in some combination of low performance, poor security controls, difficulty in deployment and management, or all of the above. Instead, we decided to decouple each of those concepts into separate layers that allow us to optimize the behavior of each layer to produce the maximum benefit, whether that is connection performance or security controls.
We describe this as a distributed network architecture, and we believe that this will become the standard way companies will design and manage access to their networks over the coming years.
Let’s take a look at each of these layers and describe how they work in the context of Twingate:
Three layers of Twingate network architecture
The Network Layer
This refers to the complete set of resources and devices that can potentially connect to each other. No existing interconnection between this set of nodes is necessary and individual nodes in this layer can exist in any network or geography. The combination of the control and transport layers (described below) ensures that only authorized clients can access assigned resources.
Clients and resources can access the control and transport layers directly via an embedded library, client application, or a lightweight proxy. These components perform a few critical functions:
Policy enforcement: rules passed down by the control layer are enforced locally without any traffic needing to leave the device.
Routing: route selections are executed locally to deliver the best connectivity performance.
Security: implement security controls such as enforcing allow/deny lists or implementing secure DNS.
Most importantly, no node in the network needs to be exposed to the public internet.
The Control Layer
This layer is responsible for defining the rules governing which nodes in the network can communicate with each other. While this control layer needs to be distributed and redundant to serve low latency requests to clients and resources, no traffic passes through this layer.
The control layer performs a few critical functions:
Authentication: users and clients cannot access resources without first authenticating themselves. This is enforced and enabled by the control layer, and it interfaces to an identity authority (e.g., Okta) for authentication.
Policy definition: policies are defined in the control layer (e.g., via a web-based admin console or the admin API) and subsequently passed down to the network nodes for enforcement and execution.
The Transport Layer
This layer is responsible for facilitating the optimal route from any client to any resource and serves two primary functions:
Signaling channel for peer-to-peer connections: By default, the transport layer attempts to establish a direct, peer-to-peer connection between the client and the resource. This is achieved by using a signaling channel to directly orchestrate a connection between the two nodes. If either or both nodes are behind a firewall, then a range of NAT traversal techniques are used to establish a direct, end-to-end encrypted connection between client and resource.
Serves as a backup transport channel to relay encrypted traffic: If a peer-to-peer connection cannot be established, the transport layer can take over relaying encrypted traffic between the client and resource. Although this appears similar in structure to the Cloud Network architecture described above, a key difference is that all routing and authorization decisions are made directly in the client and resource nodes. These decisions are enabled by the control layer and executed by the client and resource nodes, which relegates the transport layer to a zero-knowledge transfer of encrypted bytes.
In aggregate, the decoupling of these concepts into discrete concepts enables us to drive towards the optimal combination performance, security controls, and ease of management.
Next, we’ll dive deeper into the underlying network techniques to bring this architecture to life.
Twingate’s Distributed Network Architecture
As we’ve worked to implement our version of the distributed network topology, we’ve employed a range of techniques that provide optimal performance in most scenarios and reflect the reality of how people work today.
It all starts with Routing
The first problem is routing. How do you get a network connection established from a client to a resource? The easiest solution would involve every device on the Internet having a unique address so that network connections could be directly routable between any two devices. Although this is how the Internet started, with every host uniquely accessible, it was clear as early as 1992 that every unique address in the IPv4 space would soon be exhausted. With inevitable Internet address exhaustion on the horizon, a number of solutions were proposed, including Network Address Translation (NAT), which was proposed in 1994 and adopted soon thereafter. NAT was intended to be a short-term solution, with IPv6 being the long-term solution to address exhaustion. The last block of IPv4 addresses was assigned in 2011, and in 2021 we’re still waiting for the complete adoption of IPv6. NAT and IPv4 will be with us for some time to come.
For most use cases, NAT doesn’t present any particular problems. Without realizing it, everyone who uses the Internet today has their traffic constantly traversing multiple layers of NAT to access public Internet services. In this situation, a private host (a user’s device) is accessing a public host (e.g., a web server). Traffic can be exchanged by virtue of the public host having a publicly accessible endpoint that’s routable from the private host via an ISP.
Where things get interesting is when one private host wants to connect to another private host—known as a peer-to-peer connection—where, for example, two participants wish to initiate a video call, each at home behind the NAT service on their home router. Several technologies have been developed to address the issue of NAT traversal—so-called because each peer must traverse the NAT layer in front of its peer—since the earlier days of the Internet. WebRTC is one of the most well-known approaches. We’ll come back to this topic of NAT traversal techniques later on.
In our distributed network architecture, the control layer authorizes connections from any client to any resource in the network layer. If this is the end goal, and we can’t control whether clients and resources are behind a NAT layer, how can a client connect to a resource under those conditions? It turns out that there are several approaches, which we’ll go through in progressive order of complexity.
Open access: The simplest possible option is that everything should have a public IP address, which means that connecting any two hosts requires routing and nothing else. This isn’t as crazy as it sounds, but it does require a significant rethinking of how individual hosts are secured from attack by default, so this isn’t practical on today’s Internet. In the future, IPv6 will make this option more realistic.
Port forwarding: A relatively simple approach that questionably relies on security through obscurity. The approach taken here is to translate from some public IP address (your home internet router, for example) and a designated port that forwards traffic through to a private address and different port. This exposes only the necessary service(s) that you wish to make available and makes the destination routable to the public internet. Still, this approach leaves the target service and host open to public attack vectors and involves the configuration of router rules, which adds unnecessary complexity at any kind of scale.
Port knocking: Also known as Secure Packet Authorization (SPA), this technique is akin to having a secret knock to enter a Prohibition-era speakeasy, hence the technique’s name. While the actual implementation is more complex, the goal is to deter casual port scanners by leaving open ports unresponsive unless a particular sequence and timing of packets arrive to open up the specific port. It’s an effective technique, but one that leaves your host and services wide open if the packet sequence is discovered.
Data relay: Instead of developing techniques that involve opening up access to the target host from the public Internet, using a relay introduces an intermediate host publicly accessible from both the client and resource hosts. This has the advantage that the client and resource hosts can remain invisible to the public Internet. As long as a relay is available close to either host, minimal additional latency is introduced. The relay can be incorporated into the overall transport such that no connection termination occurs and streams can remain private. This approach is a standard backup method when NAT traversal techniques are unsuccessful.
Proxies: With the introduction of proxies, we’ve now departed the realm of solutions-driven purely by the routing and transport layers of networks. Proxies work by terminating network connections, either manipulating or validating the packets and payloads they receive, and sending that data forward to either a destination resource or a corresponding reverse proxy, passing data to the destination resource.
Proxies are software-based and operate in the operating system’s user space. Proxies are easily deployed and introduce a significant level of sophistication into the type of routing and transport manipulation that’s possible while often remaining transparent to the application initiating a network connection. For these reasons, proxies are the dominant solution deployed today across many applications involving network traffic management.
There are two approaches taken to deploying proxies in practice. While their underlying functionality may be identical, they differ in the tradeoffs made in their deployment.
Public proxies: Public proxies are deployed with a publicly routable address, which means that they can sit in front of a destination resource, making it accessible from clients regardless of whether they have publicly accessible addresses or not. The tradeoff here is that with the convenience of accessibility comes the burden of ensuring that the public proxy is hardened and regularly patched to prevent attacks. This is particularly true because of the role the proxy plays: if identified as a proxy from the outside, it’s an entry point that is securing something in the private network behind it.
Private proxies: Private proxies serve the same role, but they are deployed behind firewalls on a private network. There are significant security benefits to this approach—no public address and all the benefits of using a proxy in the first place—but they don’t address the issue of making resources accessible to clients because they, too, are behind a firewall. This leads us to the topic of NAT traversal, which we’ll cover next.
Punching Holes Through (Fire)walls
Since we ended with private proxies in our overview above, it’s a safe bet that we think private proxies represent the best set of tradeoffs for implementing a distributed network topology. The two primary reasons for this are that private proxies are:
Invisible to the public internet: Because they sit behind a private network’s firewall, it’s impossible to discover them via public Internet port scanning or probe them for vulnerabilities. Even if a sophisticated attacker can infer the existence of a proxy behind a firewall based on visible traffic patterns, defense in depth is a highly effective technique here by separating security concerns into an effective firewall.
Simple to deploy: Since they run as a regular user space service, they’re effortless to deploy onto virtually any available device, regardless of platform or silicon chipset. The lower security burden of private proxies also means that they’re more likely to be deployed when needed. Successful adoption of a given approach is also an essential factor in overall security posture.
The last puzzle piece is figuring out how to make these proxies accessible to clients who wish to connect to the destination resources they protect: enter NAT traversal. Because NAT has been implemented across Internet-connected networks for several decades, the range of solutions available to solve the problem of two hosts, each behind a NAT layer, establishing a peer-to-peer connection is fairly mature today. We won’t go into depth here but instead, cover the high-level steps involved in establishing a peer-to-peer connection via NAT traversal.
Twingate NAT traversal process
The NAT traversal process is divided into four primary stages:
Establish a signaling channel: On initial startup, both the client and private proxy—known as the connector in Twingate’s architecture—initiate and establish an authenticated connection to a central service that is publicly accessible. The initial role of this service is to establish a signaling channel for the exchange of peer candidate addresses to each peer. In Twingate’s architecture, our existing authenticated relay infrastructure—already distributed globally—is used to establish a signaling channel.
Discover peer candidate addresses: For the client to negotiate a peer-to-peer connection with a connector, both peers must discover their public IP:port address assigned by the NAT layer. A STUN server facilitates this process and is hosted on our relay infrastructure.
Exchange candidate peer addresses: Each peer next receives one or more candidate addresses for its peer via the signaling channel. The connector will receive candidate address(es) for the client and vice-versa.
Negotiate & establish the connection: The peer candidate addresses are used by the partner peer to attempt to establish a direct peer-to-peer connection and complete the NAT traversal process.
Putting it all together
It’s not always possible to establish a direct peer-to-peer connection for various reasons, from blocked ports to incompatible NAT layers. In that case, a backup data transport method needs to be maintained. In Twingate’s case, this is a data relay infrastructure that operates in the transport layer of our network architecture. Relays have public addresses, so they are always accessible from clients and deployed connectors, serving as a reliable backup transport method.
In summary:
Private proxies provide the best set of tradeoffs between security and flexibility to specifically deploy into the private networks where access is needed.
NAT traversal is used to create a peer-to-peer connection between clients and resources to minimize latency.
Relaying infrastructure is available as a backup transport method when NAT traversal is not possible.
Twingate automatically prioritizes the lowest latency transport option that’s available between peers.
One more thing…
We mentioned above that proxies provide the opportunity to introduce a significant level of sophistication into network traffic management. We’ve taken advantage of that to introduce QUIC, a new transport layer network protocol, into our peer-to-peer connections. QUIC introduces several improvements to our transport layer, including faster connection establishment, greater tolerance to network changes—a dominant mode standard in today’s world of mobile devices—and more effective traffic management of multiple, concurrent data streams. User space network stack implementations like QUIC can evolve more quickly than their kernel space counterparts, and we’re excited to participate in this fast-paced evolution.
QUIC was originally developed by Google and has since been standardized by IETF in RFC 9000 and proposed as the underlying transport protocol for HTTP/3. One of the primary goals of QUIC was to become a better transport mechanism for HTTP/2, which suffers from the so-called head of line blocking problem due to its use of TCP as the underlying transport protocol. The head of line blocking problem occurs when all HTTP/2 streams multiplexed over a single TCP connection are impacted by retransmission due to packet loss affecting only a subset of streams.
QUIC is built on top of UDP, which is an unreliable network protocol, and so it provides its own reliable delivery mechanisms. QUIC provides reliable and ordered delivery of multiple concurrent data streams by multiplexing them over a single connection.
Twingate's QUIC Transport
Although TCP implementations have been highly optimized over many years, for many users and use cases, QUIC’s low latency is arguably more critical than raw throughput, and QUIC can match or exceed TCP+TLS in this respect. Thanks to QUIC’s adoption, there are also ongoing efforts to optimize UDP performance in the Linux kernel, which will further improve performance in the future.
The motivation behind the development of QUIC—to improve the throughput of multiple streams on a single reliable connection—is also valuable to maximizing throughput from the Twingate client to multiple private resources. Although QUIC was envisioned to optimize the throughput of multiple streams for a single application (e.g., your browser), Twingate extends this concept by mapping individual data flows from any number of applications to single QUIC streams and delivering those data flows to connectors and resources deployed anywhere in our distributed architecture.
Beyond performance management for multiple data flows, adopting QUIC also introduces several valuable improvements to our network architecture:
Faster connection establishment: The initial connection takes a single round trip between client and server. Connection resumption can also be done without any additional round-trip negotiation.
Support for the latest cryptographic protocols: QUIC only supports TLS 1.3 and later, and introduces additional security into the encrypted channel.
Client-side roaming: QUIC connections survive client-side IP and port changes—for example, due to NAT rebinding or a user switching between networks—which not only results in a better experience for users but is also better suited for today’s mobile work environment.
Incorporates best practices from TCP: Although QUIC is a UDP-based protocol, it contains the best practices learned over the long history of the TCP protocol without being restricted by TCP’s legacy (e.g., packet format). For example, QUIC is usually more efficient than TCP in dealing with packet loss recovery.
Try Twingate for Free
We’re thrilled by the reception Twingate has received since our launch in 2020. If you’re interested in taking Twingate for a spin, we just launched a free tier where you can implement our secure access solution for your startup, home network, or personal projects. Of course, we also have business plans if you’re interested in moving off VPN for your company.
Solutions
Solutions
The VPN replacement your workforce will love.
Solutions